When building a machine learning model, ensuring it performs well on new, unseen data is just as important as training it on existing data. One essential concept that helps achieve this is cross-validation. It is a key technique in model evaluation that helps prevent overfitting and gives a more reliable measure of a model’s performance. This concept is often covered in depth in programs like the Data Analyst Course in Trivandrum at FITA Academy, where learners gain hands-on experience with real-world datasets and industry-relevant tools.
Let’s explore what cross-validation is, why it’s important, and how it improves model accuracy in data analytics and machine learning.
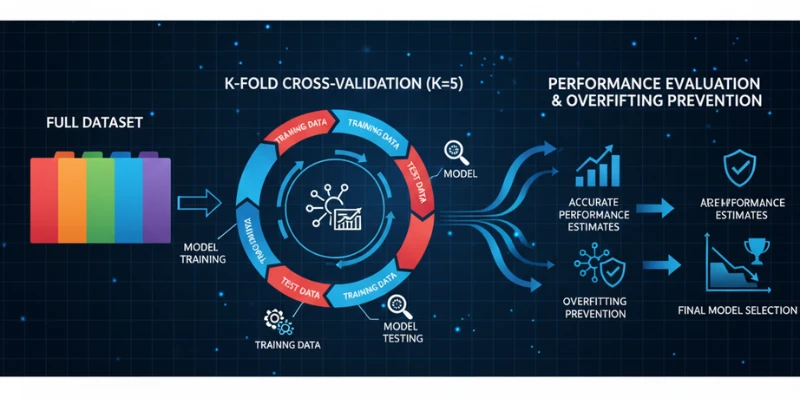
What is Cross-Validation?
Cross-validation is a method used in statistics to evaluate how effectively a model will perform on unseen data. It entails splitting the original dataset into smaller groups, training the model on a portion of those groups, and testing it on the others. This process is repeated several times to ensure consistency and fairness in evaluation.
The most frequently used method is known as k-fold cross-validation. In this approach, the data is divided into k equal segments or “folds.” The model is developed using k-1 folds and evaluated on the leftover fold. This procedure is carried out k times, utilizing each fold once as the test set. The final model accuracy is the average of all the individual test results.
Why Cross-Validation Matters
1. Prevents Overfitting
Overfitting occurs when a model becomes too familiar with the training data, capturing even the noise and outliers. This leads to high performance on the training set but poor results on new data. Cross-validation helps detect this by testing the model on multiple subsets. If the model performs consistently across all folds, it’s less likely to be overfitting. Acquire essential knowledge such as cross-validation and discover how to create models that excel in practical applications by signing up for the Data Analytics Course in Cochin.
2. Reliable Performance Estimates
Without cross-validation, using a single train-test split might give misleading results. The choice of test data could either favor or disadvantage the model, depending on the randomness of the split. Cross-validation gives a more balanced view by using every data point for both training and testing across different rounds.
3. Efficient Use of Data
In cases where the dataset is small, cross-validation allows you to make the most of the available data. Since each data point is used for both training and testing at different stages, it ensures the model is evaluated on all parts of the dataset, maximizing the value of every observation.
Types of Cross-Validation
While k-fold cross-validation is the most popular method, there are other variations worth mentioning:
- Stratified k-Fold: Ensures each fold has the same proportion of target classes, which is useful for imbalanced datasets.
- Leave-One-Out (LOO): A special case of k-fold where k equals the number of data points. It is more accurate but computationally expensive.
- Repeated k-Fold: Repeats the k-fold process multiple times with different data splits to get a more stable estimate.
Each method has its strengths, but all aim to provide a more accurate picture of how well a model generalizes. To learn more about this concept, join a Data Analyst Course in Pune, where students learn to apply these techniques in practical analytics projects.
Improving Model Accuracy with Cross-Validation
Model accuracy is not just about high performance on training data. It’s about how well the model can make predictions on real-world data it has never seen. Cross-validation directly addresses this concern by simulating real-world scenarios during the evaluation process.
By using cross-validation, data scientists can confidently choose between models or tune hyperparameters, knowing that the performance results are based on thorough and fair testing. This leads to better decision-making and more accurate, robust models.
Cross-validation is a vital part of any data analytics or machine learning workflow. It prevents overfitting, provides reliable performance estimates, and makes efficient use of limited data. Most importantly, it helps improve model accuracy by offering a realistic assessment of how the model will perform in production.
For anyone serious about building models that generalize well and deliver reliable results, understanding and applying cross-validation is not optional. Gain hands-on experience with essential techniques like cross-validation by joining the Data Analytics Course in Chandigarh and start building practical, industry-ready skills.
Also check: Mastering Data Analytics for Smarter Insights